Tokens and AI agents are changing the rules of the game. Big Techs are betting on AI factories

Yes, ChatGPT has changed the world of technology and the service boasts the fastest growing user base in history. However, it is hardly surprising that there is skepticism among people who associate AI mainly with ChatGPT, and when they see OpenAI's finances and hear about investments in data centers amounting to hundreds of billions of dollars, they wonder how it all is calculated. According to the corporations at the center of the multi-billion dollar AI “bubble”. However, the key is not chatbots and subscriptions to them, but the sale of tokens generated by the language model while performing specific tasks or work. In other words, from providing customers with computing power used to run AI agents.
Let's start with this what exactly is a token?. To put it very briefly and simplified, it is this basic calculation and settlement unit all large language models. AI creates them by performing calculations on accelerators when we ask it a question or give a command. When we talk about text generation, one token is on average about four characters, which corresponds to very small amounts of data. This is why multimedia generation is so severely limited in subscriptions to popular AI services, because it consumes very large amounts of tokens, which means that it burdens very expensive accelerators for a long time, currently consuming from several hundred to over 1 kW each.
If the limits of the classic and well-known subscription plans are not enough for someone, then… AI service providers also have a second price list in which they provide a price for, for example, one million input and output tokens.
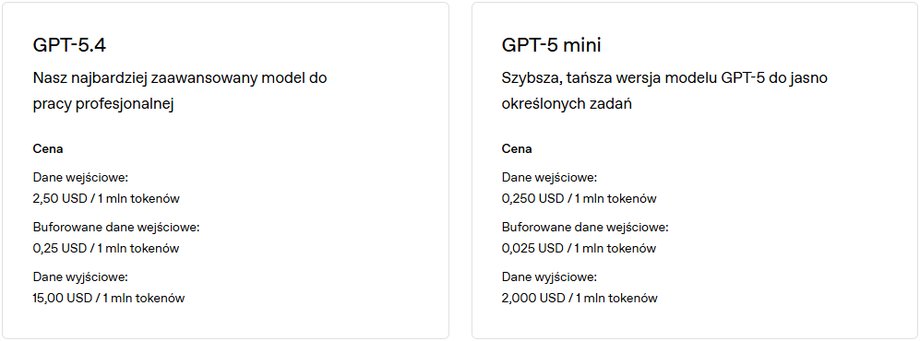
Sample token price list. It is worth paying attention to how much the price varies depending on the selected model.
|
Onet
On the side of the data center operator, the cost of the token depends on a certain fixed cost (the cost of building a server room and filling it with accelerators, or the cost of training the model), and then on how much time it took and how much energy was used to generate it. This is why big tech companies are rushing towards the next generations of Nvidia's AI systems, because although they are very expensive (according to analysts' estimates, a single Vera Rubin system is worth over $4 million), they can generate even many times more tokens from each watt of energy supplied to them and dollar spent on them than their predecessors. Since this is similar to the situation with the production of physical goods, data centers specialized in handling tokens and generating as many tokens as possible in the shortest possible time and at the lowest price are increasingly becoming they are called token factories or AI factories.
On the client side, assessing the value of the generated token is more complicated and inextricably linked to the language model used, because each model in some sense generates tokens of a different quality — a language model good enough to talk to about the weather may be completely unsuitable for serious market analysis, even if you give it unlimited time and an infinite number of tokens. Some will also pay a premium for speed of response.
Although new generations of language models are constantly being optimized, which means that the tokens they generate are both cheaper and of better quality than when we first saw ChatGPT, within the same generation and type of models the rule is still simple: the more advanced the model that provides better quality answers and the faster you want to generate them, the greater the demand for computing power.
This economic balance between demand, supply, unit cost of the token and its usefulness from the customer's point of view it is commonly called tokenomics.
The Claude Code and OpenClaw revolution brings an exponential increase in token consumption
Token pricing has actually been around as long as the current version of AI based on large language models, and the concept of tokenomics itself is not new either. Why is there so much talk about this now? Mainly because of the gigantic investments in AI infrastructure mentioned in the introduction, which are driven by the fact that the demand and consumption of tokens has been growing very rapidly for some time.
The above-mentioned increase in demand for tokens and the belief that it will continue to grow, making it worth investing nearly a trillion dollars in the construction of data centers now, is inextricably linked to the emergence of the first useful AI agents. In corporate applications The breakthrough moment was the release of the Claude Code tool by Anthropicwhile from a consumer point of view, the breakthrough was the appearance of the Clawdbot tool, now known as OpenClaw.
Claude Code is an inconspicuous-looking tool that caused a huge stir.
|
Onet
In (next in this article) gross simplification, the difference between a chatbot and an AI agent is: the chatbot gives the user an answer, and the agent acts on his behalf. AI agents also increasingly communicate with other applications and tools. The aforementioned Claude Code is often described as the first truly useful AI agent for the reason that, thanks to a few clever solutions and the high quality of the language model behind it, it became possible to automatically perform much more complex, multi-step tasks that previous tools would have simply gotten lost and either raised a white flag or started hallucinating incessantly. In practice, this has dramatically increased the number of potential applications for AI, especially in business. Initially, Claude Code irreversibly changed the work of programmers, but over time it turned out that this tool was great at handling and analyzing large amounts of data. Clawdbot/OpenClaw later showed that these mechanisms could also be used in more consumer applications and thus automate many everyday tasks.
Hook? Such agentic tasks — often lasting hours due to subsequent iterations being called to check the effect of the previous iteration and making corrections — they consume very large amounts of tokens. Additionally, it is possible to run more than one agent at the same time, which further drives the demand for tokens, because each user can use many times more of them than before.
The scale of this phenomenon is demonstrated by Anthropic's results. At the beginning of last year, Anthropic had annual run-rate revenue of approximately $1 billion. Now, some 14 months later, it is already about $20 billion. The most interesting thing is that it would be even bigger if only Anthropic had more computing power at its disposal.
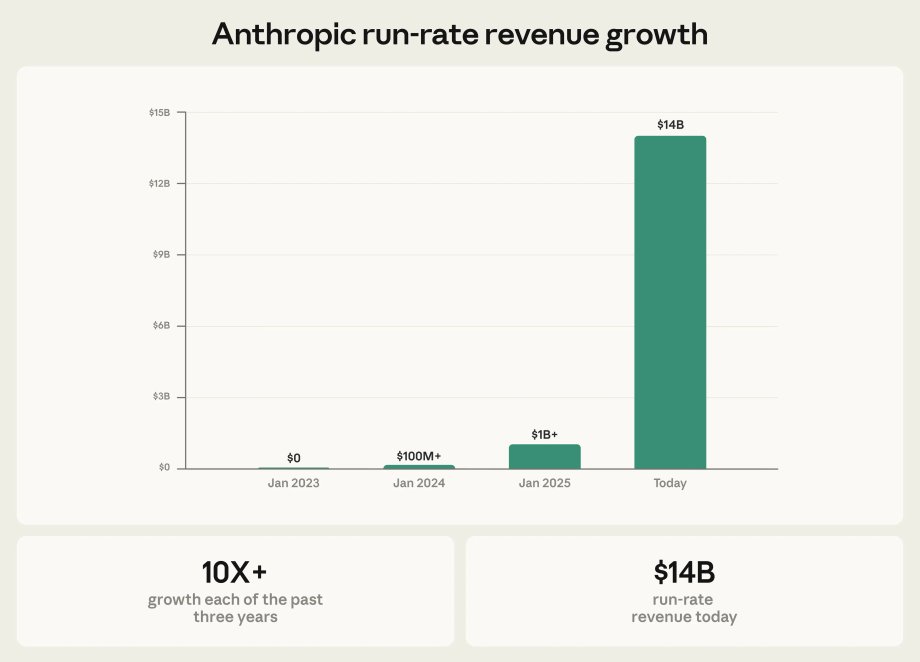
In mid-February, Anthropic boasted an ARR of $14 billion. It is currently estimated to be around $20 billion.
However, this is not the only company in a similar situation. During the last financial report, the head of Nvidia said that we live in times in which More computing power equals more revenuebecause the demand for new computing power drastically exceeds the supply provided by existing data centers. Therefore, he believes that the USD 700 billion that the five largest data center operators intend to invest in infrastructure this year is only the beginning of the expenses. Of course, it must be taken into account that Jensen Huang wants his investors to think so, but many market signals indicate that we may actually be dealing with a new version of the Jevons paradox and tokenomics does not intend to slow down.
Not subscription sellers, but virtual “employment agencies”
In the dream version of the future of companies such as Anthropic (but also other companies dealing with software and services that will have their own AI agents operating on their data and tools), this paradox will lead to a situation in which they are no longer sellers of subscriptions giving access to chatbots or individual tools, but virtual employment agencies having in their “ranks” a highly qualified workforce that is employed by paying for the tokens it uses. However, the size and capabilities of this workforce, and therefore also potential earnings, are directly proportional to the computing power available. Dario Amodei, the head of Anthropica, regularly says that thanks to AI, we will soon have entire nations of experts with the intelligence of Nobel Prize winners.
This is the theory, and the more you have dealt with tools such as Claude Code and OpenClaw, the easier it is to believe that huge expenditures on new data centers make sense. However, this does not change the fact that although for now we are dealing with the Jevons paradox mentioned above – i.e. a situation in which an increase in the quality and a decrease in the unit cost of tokens drives the demand for them, because thanks to this, new applications for them appear – one day we will reach the ceiling of this demand and no one knows exactly where it is.
This does not change the fact that although companies like Anthropic and OpenAI They are happy to talk about their income, but they are reluctant to talk about it because they do not have it. For now, the biggest earners from AI are hardware developers (Nvidia) and companies such as Meta and Alphabet, which have been using artificial intelligence to optimize their advertising business for years, which AI is doing very well. So we are still at the stage of assumptions, promises of a quick solution to the problems plaguing AI and estimates. The accuracy of these assumptions, promises and estimates in the future will divide the world of technology into winners and losers of one of the largest investment cycles in human history.





