Chatbots and devour data. The greatest threat is Meta AI – both for employees and companies

The Surfshark report compared ten popular AI chatbots in terms of the scope of user data, which the mobile applications of these services acquire. It is worth adding that these data are declared in the “App Privacy” section on the Apple App Store. The results are not optimistic. All analyzed applications collect some user data, and on average collect 13 out of 35 possible data categories.
Up to 45 percent Chatbot surveyed obtains information about the location of the user, and almost 30 percent. Uses tracking (connecting data from applications with third -party data for advertising purposes). Even if we use chatbot only to ask questions, the background application can read and send a number of information from our device and account to the servers.
Meta AI turned out to be the leader in collecting data – AI assistant from Meta (Facebook, WhatsApp, Instagram, Threads). The application collects 32 out of 35 possible data types, i.e. over 90 percent. all analyzed categories.
For comparison, this is the most of the entire chatbot rate. Meta AI collects not only basic contact or diagnostic details, but As the only one, he also reaches for information from the particularly confidential category, including Financial, health and even sensitive personal data, such as ethnic origin, religious or political views or sexual orientation.
This makes her the most aggressive “eater” in the list. According to the report, Meta AI is also the only application (next to one of the Copilot versions from Microsoft) collecting data related to the user's identity to present third -party ads.
Check also: There was supposed to be AI, there were people from the Philippines. Investors must watch out for fraudulent start-ups
The finish is the worst. What next?
More chatbots were in the ranking. Google Gemini came second, which collects as many as 22 different data types – including as sensitive as the exact location of the user's GPS.
Further places include Poe (Chatbot platform from Quora), Claude AI (model from Anthropic) and Microsoft Copilot. All these applications also belong to the most pouring for user data.
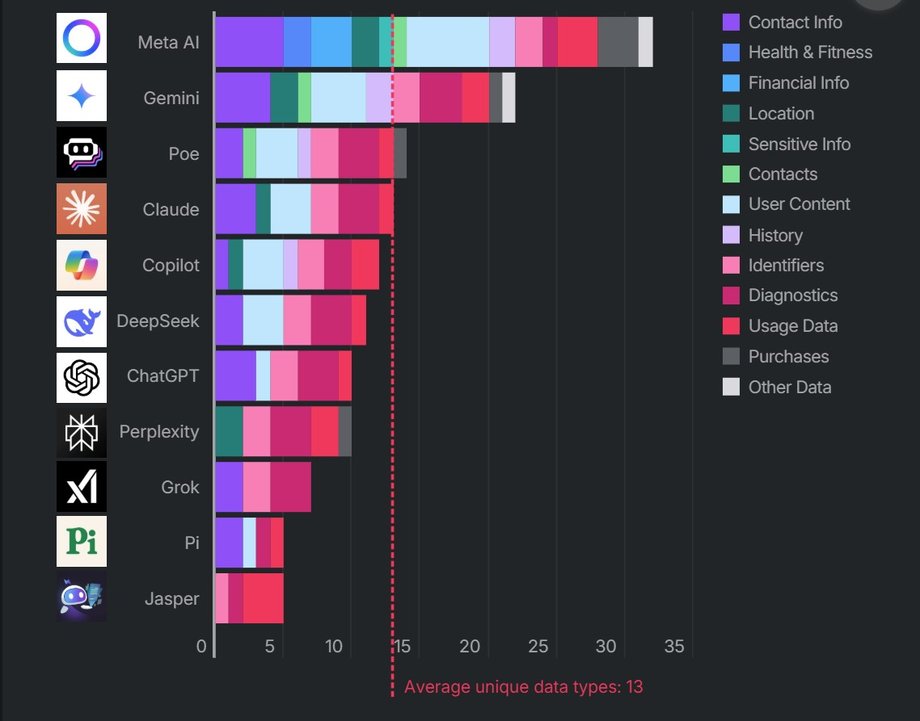
The result of the Surfsharek report. The most user data is used by Meta AI, and Google Gemini is in second place
|
Surfshark
Importantly, Copilot turned out – next to Meta AI – the only chatbot obtaining data directly related to the user's identity to display ads (Copilot uses, among others, device identifiers and marketing data). In turn, POE (and the mentioned Copilot) were caught on sharing detail identifiers to brokers – this means that the data about the user's device could have been sent to entities trading information about Internet users.
Against this background, more famous chatbots like ChatgPT are slightly better. The official CHATGPT application collects “only” 10 data categories (including user contact details, conversations, identifiers and operational data), and avoids tracking the user and external ads.
Opeli even allows you to disable saving the history of chats or automatically delete the content of conversations after 30 days. Nevertheless nAwet Chatgpt is not completely safe from the point of view of companies. Reason? Part of the information (e.g. logs) is still stored temporarily on the supplier's servers, and the very fact of collecting 10 types of data indicates that the application tracks the user more than you might think.
The overall tone of the Surfshark report is bright. Each of the popular chatbots processes and collects our data, although the scale of this phenomenon varies depending on the supplier. Unfortunately, for users – including enterprises – full transparency as to how this data is used, often remains only in the sphere of declaration in the Privacy Policy.
Read also: Shorter full -time, the same performance. And will help companies balance a six -hour working day
Risks for companies, i.e. when confidential data goes to external servers
From a business point of view, the above findings should light a warning lamp. The use of AI chatbots, which intensively collect data, carries significant risks for companies, especially if employees process official information with their help.
In the corporate environment, data is a sensitive resource. Customer databases, project details, internal correspondence, contracts and documentation – leakage or improper use of such information may have serious consequences legal and financial. Meanwhile, using popular chatbots, companies de facto transfer fragments of their data to external AI service providers.
As a result, any question asked to chatbot can, as a result, power his knowledge base or logs on the supplier's servers. If, for example, the personal data of clients or the details of the contract includes the personal data, this content leaves the secured company environment and goes to the cloud of a foreign entity. The consequences of this situation can be serious.
First, loss of control over data – The company has no guarantee whether the information entered to Chatbot will remain confidential. The supplier can store them for some time, use to continue training models or even make available to third parties (as is the case with applications tracking applications for advertising purposes).
Secondly, there is a risk of data leakage. Surfshark directly warns that conversations stored on servers are always exposed for potential security violations.
This warning is not purely theoretical – in the case of the Chinese Deepseek platform there has already been an incident in which over a million records of chats history leaked with the keys of API and other data.
Each similar incident means a threat to the company that confidential information (e.g. about clients or business plans) will become publicly accessible or hit the wrong hands.
Thirdly, companies must take into account legal requirements and compliance with regulations. Sending customer or employees to the external AI service may violate the provisions on the protection of personal data (GDPR) or internal security policies. Banks, financial institutions and sensitive entities (e.g. from the health sector) are afraid that the unauthorized disclosure of information by Chatbot could result in supervisory sanctions.
It is not surprising, therefore, that some corporations introduce restrictions. For example, Samsung banned its employees to use chatgpt after it turned out that the engineers introduced fragments of the internal source code to it, as a result of which confidential data left the company. Similarly, large banks, like JPMorgan or Goldman Sachs, blocked employees access to chatgpt For fear of removing sensitive information outside the company.
See also: She threatened and blackmailed employees. The latest artificial intelligence Anthropic is extremely powerful
How to secure company data? Local models and infrastructure
Since the collection of data through external chatbots poses a threat, a natural question is what can be done to prevent it. The first step is, of course, a caution policy. Companies should clearly communicate to employees what types of information cannot be disclosed in conversations with public chatbots. Education and awareness are necessary here. Every employee should know that throwing a fragment of a customer database or a contract of a contract is tantamount to transferring this data to a foreign company.
Many organizations implement internal regulations or technical solutions blocking access to this type of service on company devices. In the long run, however, it is to develop your own AI models operating within the closed infrastructure of the company. Thanks to this The company may benefit from AI (automation, speed acceleration, intelligent data analysis) without providing sensitive information outside. Technically speaking, this is increasingly achievable – in recent years many language models (LLM) Open Source have appeared, which match the commercial capabilities of chatbots, and can be launched on your own servers.
Examples are the Mistral 7B, Llam (and its newer versions from Meta), Falcon or the experimental Mixture-of-Experts Mixtral model. There are also projects like OpenChat that develop open chatbots. Such models can be adapted to your needs, e.g. through complementary training on company data and documentsthat they would answer specific questions from a given industry better. The advantage of the launched model locally is full control over data. All queries and processed information remain on the company's servers, they are not transmitted anywhere or analyzed by external algorithms.
In other words, using its own AI model, the company gains maximum privacy and control, avoiding the risk of leakage or data abuse by a third party.
What's more, the model can be tuned to the safety requirements of the organization and meeting specific standards (e.g. mask personal data, log in each question for audit purposes, etc.). Of course, the implementation of the local AI model requires investment – you need appropriate infrastructure (servers with efficient GPU) and competences in the field of Machine Learning and AI. In return, however, we gain independence from external suppliers and the possibility of full personalization. It should also be emphasized that Already, some enterprises decide on this approach, e.g. banks create their own natural chatbots, trained on the basis of internal procedures and domain knowledge, instead of using the model in the cloud.
Open models available (like Llam, Falcon or Mistral) give it a solid base – they can be freely tunted and implemented in your own IT environment, which ensures both privacy and adaptation to the specifics of the industry. For example, the model can be taught the language of the company's legal documents or customer service procedures. Thanks to this, he will become an internal virtual assistant who knows the realities of the organization better than general chatgpt.
To later provide such a model with employees in a convenient form, you do not need for several months of programming works. There are tools and frameworks that make it easier to create a private chatbot application based on a company model. The programmer can prepare a simple web application with a chatgpt interface, which will communicate with the LLM model launched on a company server. Solutions such as Streamlit or Gradio are helpful here-they allow you to build an interactive front-end to the model, available through the browser in a short time. You can also use replit platforms to quickly prototype such an application and test its operation. The final effect is the internal chatbot AI, available only to authorized people in the organization, operating in a closed network and servicing queries based on the accumulated knowledge of the company.
Such an application may look and act similarly to public chatbots (like chatgpt or gemini), but the most important The difference is that no information entered into it leave the company infrastructure.
However, only closed infrastructure, the so -called On-PREMISE, guarantees full control over data, which makes it optimal for enterprises attaching importance to information security.
Author: Grzegorz Kubera, Business Insider Polska journalist





